Streamline Data Engineering


Collaboration and Version Control Support
Job Scheduling and job automation
Monitoring, alerting, and error handling
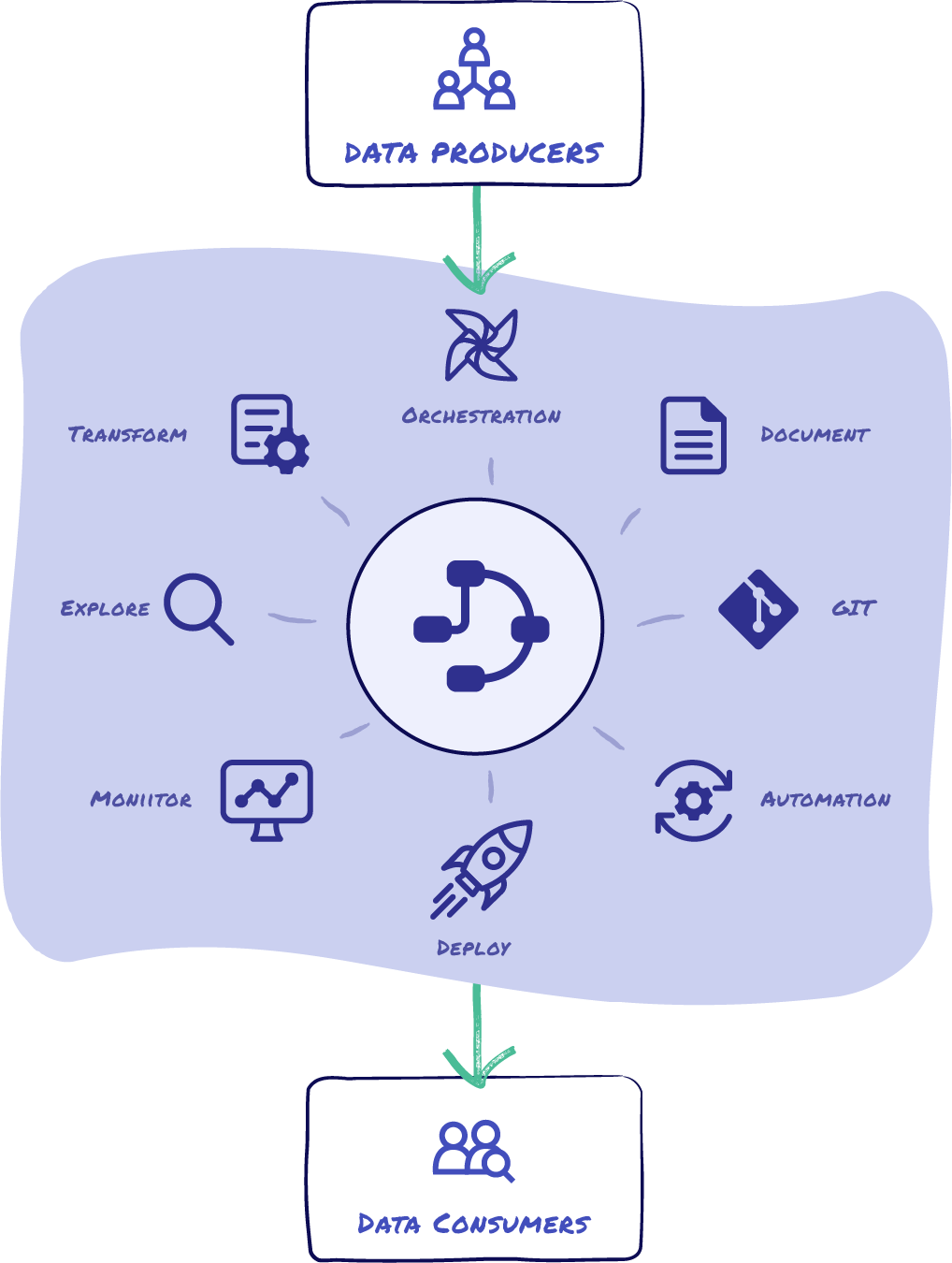
Create Reliable Data Products With an End-to-End Data Management Platform
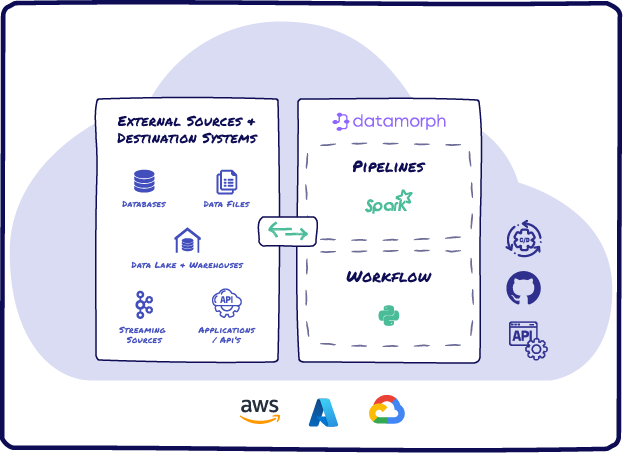
DataMorph does the Extraction, Loading, Transformation (ELT) and orchestration in a single platform, greatly simplifying your data product creation process. DataMorph provides you a visual canvas of operators and SQL snippets to create complex data pipelines and workflows. DataMorph translates these pipelines to run in Spark, the most efficient transformation engine, to get the most out of your cloud data platform and without the data team needing to learn advanced dependencies and scaling techniques.
How DataMorph speeds up reliable Data Product creation:
- Extract and Load data from hundreds of sources and sinks with out-of-the-box integrations.
- Pre-built transformation processors accelerate deployment of complex use cases such as slowly changing dimensions, schema evolution, and real-time analytics.
- Seamless integration to all Spark and orchestration runtimes including Databricks, AWS EMR, Kubernetes, Airflow, Prefect and Dagster for deployment and execution of data workflows.
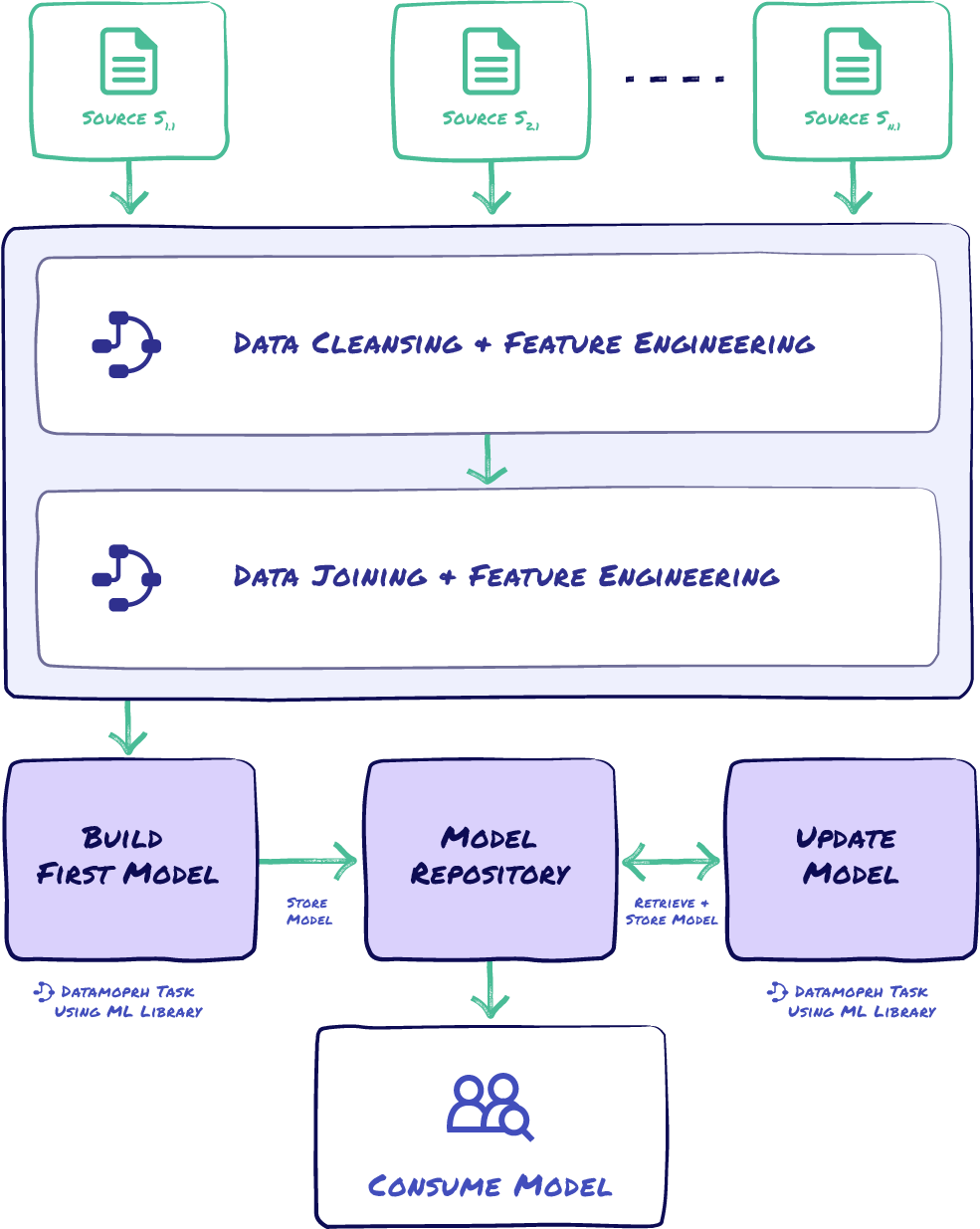
Faster Data Modeling and Machine Learning
DataMorph provides a common foundation and framework for both data engineers and data scientists to collaborate and bring ML projects to production faster. By bringing together data pipeline creation, visual + SQL data transformations, and workflow orchestration into a single platform, DataMorph breaks down the silos of data engineers and data scientists so they can release business impacting solutions faster.
How DataMorph enables faster data modeling and ML projects:
- Create a task with PySpark code and add the task to existing workflows to test, deploy and run your data model.
- Workflows makes it easier to maintain test environments and create repeatable processes to sync production code back to upstream development environments.
- Rapid model iteration using built-in software engineering best practices for git revision control and CI/CD.
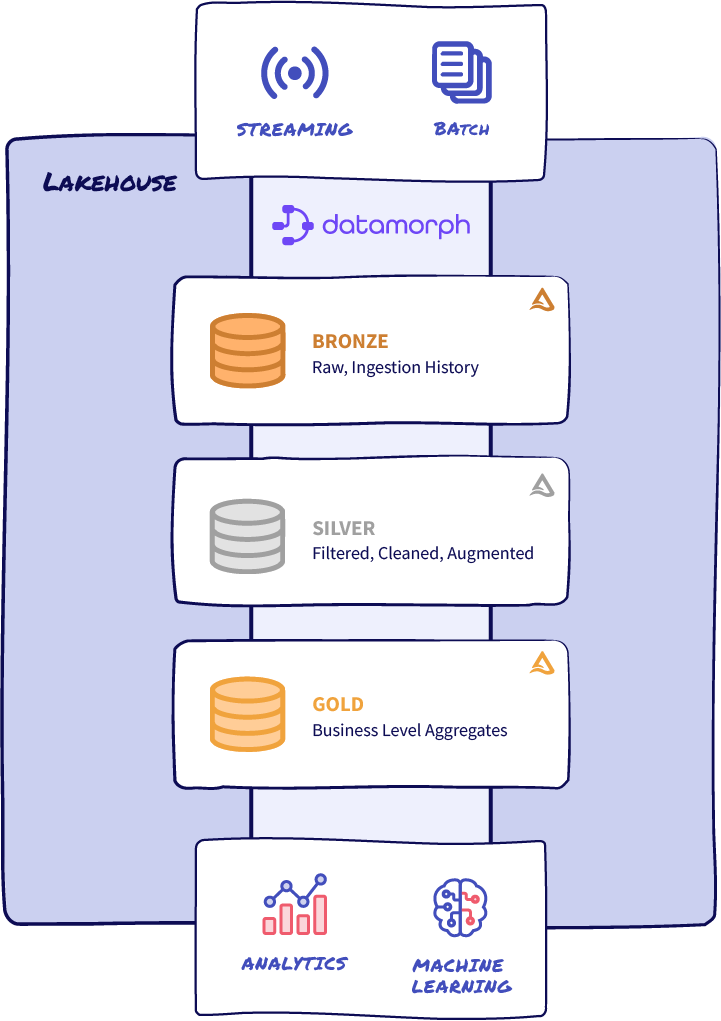
Adopt Lakehouse and Medallion Architecture at Your Pace
DataMorph platform gives you the flexibility to adopt the latest data management best practices at the speed right for your business. DataMorph helps you modernize and migrate to newer platforms while having a stable front-end for data engineers, data scientists, and business analysts to continue delivering insight for stakeholders.
How DataMorph helps you adopt a modern data architecture and orchestration:
- A visual interface which supports the full progression of data from raw, unrefined data, through the steps of refining that data, and ultimately delivering optimized data for consumption by various personas.
- An intuitive administration console for managing SSO integration, user and role management, configuring Spark and Workflow runtimes, project and profile configuration.
- Visually orchestrate your workflows with dozens of prebuilt triggers, fully customizable actions, and notifications to choose from.
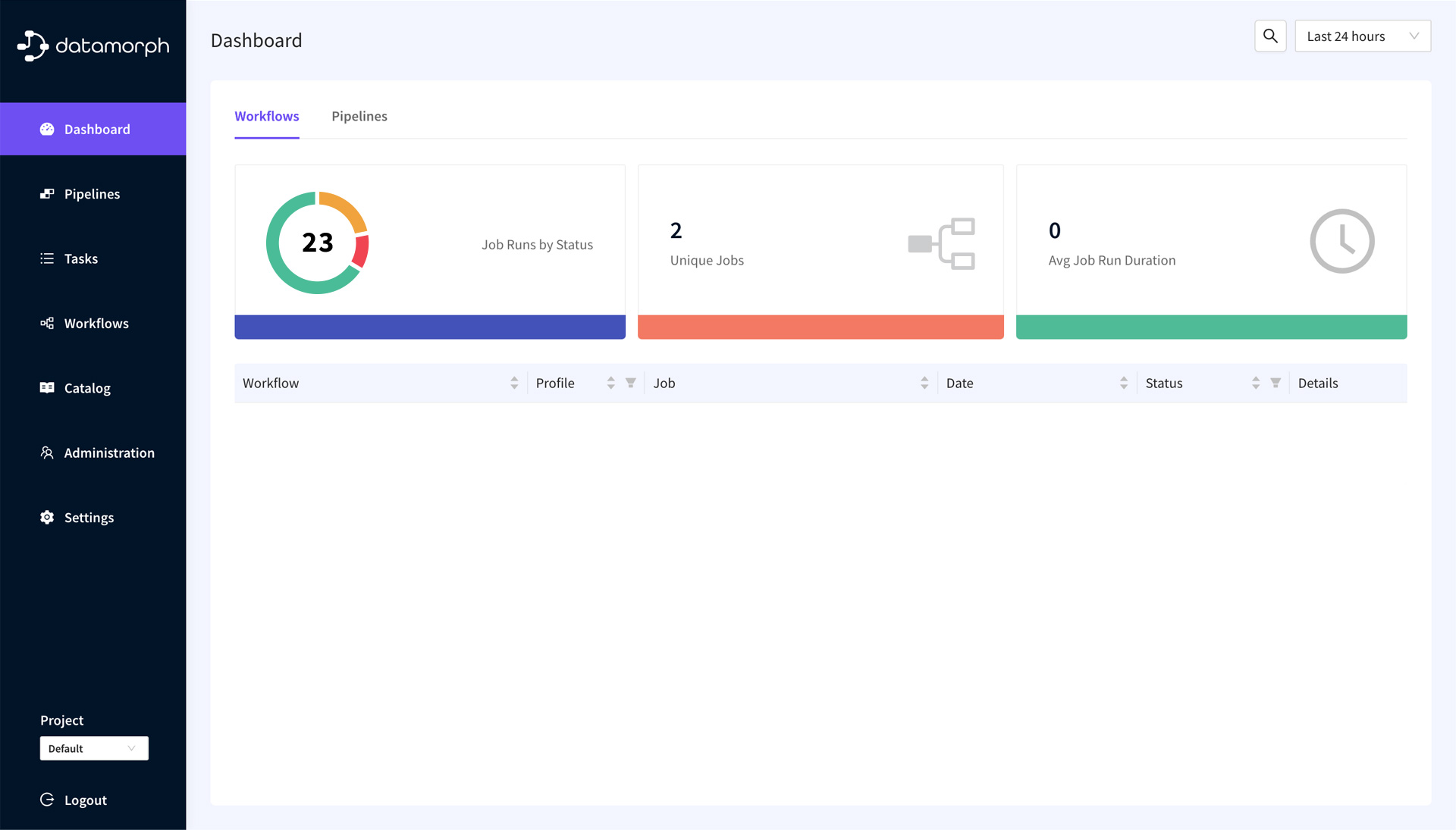
DataMorph at a Glance
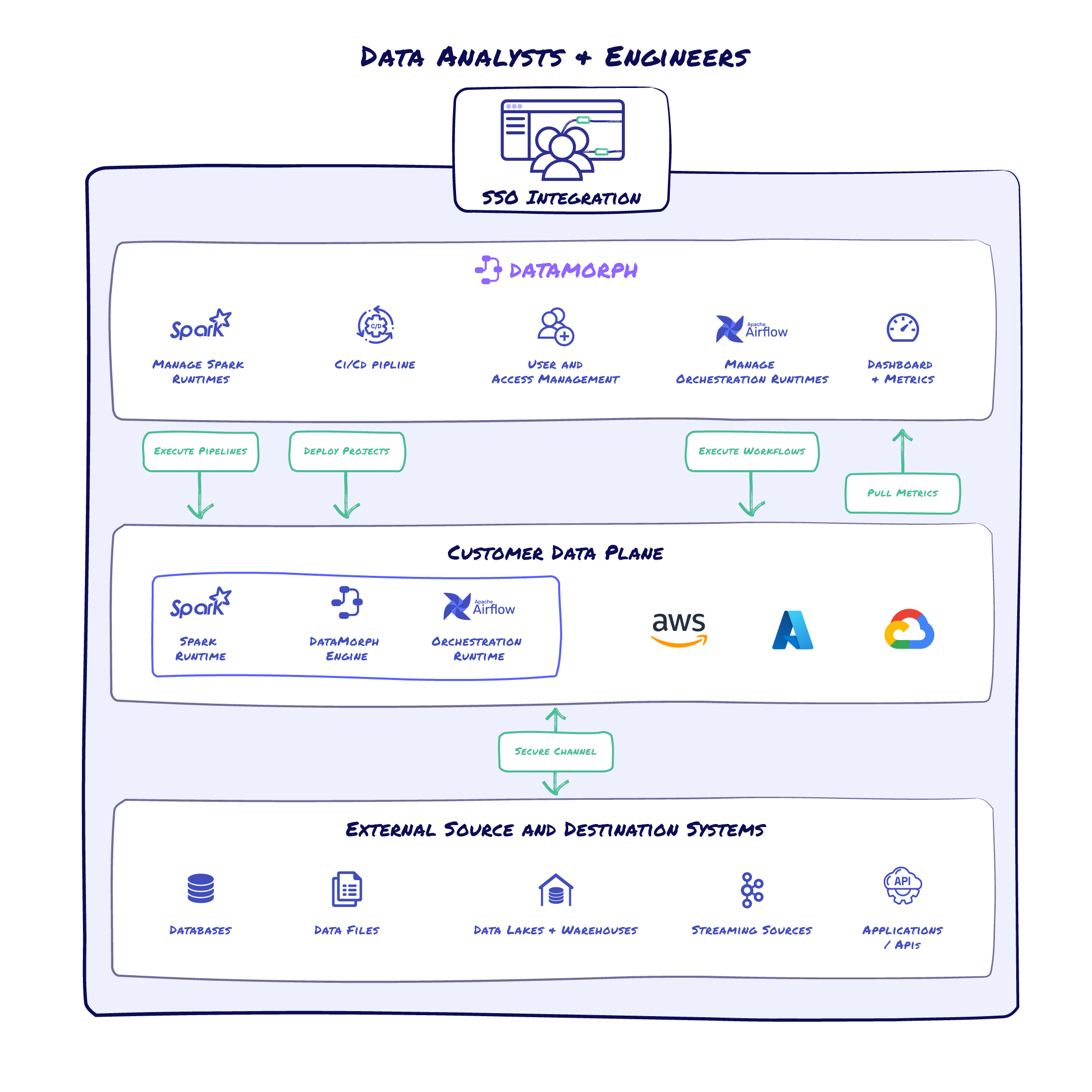
Advanced Architecture
DataMorph users interact with our web-based UI for developing and deploying data projects, and running pipelines and workflows.
The control plane, hosted by DataMorph, manages and supports
- User authentication and authorization
- Spark and Orchestration runtimes
- Continuous deployment and version control
- Scheduling of workflows and pipelines
- Monitoring and alerting
The data plane sits in your cloud environment, and DataMorph never has direct access to the data. The DataMorph engine and Spark and Orchestration runtimes are provisioned in your secure environment and manage the provisioning, scaling, and execution of data workflows and pipelines, as created in the control plane.
Pipelines
Data pipelines can be used to move data between systems, to read, transform and output data into formats that make data analysis easy. Data pipelines can also perform a variety of other important data-related tasks like data quality checks and schema evolution.
- Canvas with drag-and-drop interface for defining pipelines
- Pre-built connectors to access data from various data sources and output to multiple destinations
- Use SQL and other provided processors to transform data
- Validate and test pipelines locally before deploying to a Spark runtime
- Support for Databricks, AWS EMR, Spark on Kubernetes and other Spark runtimes
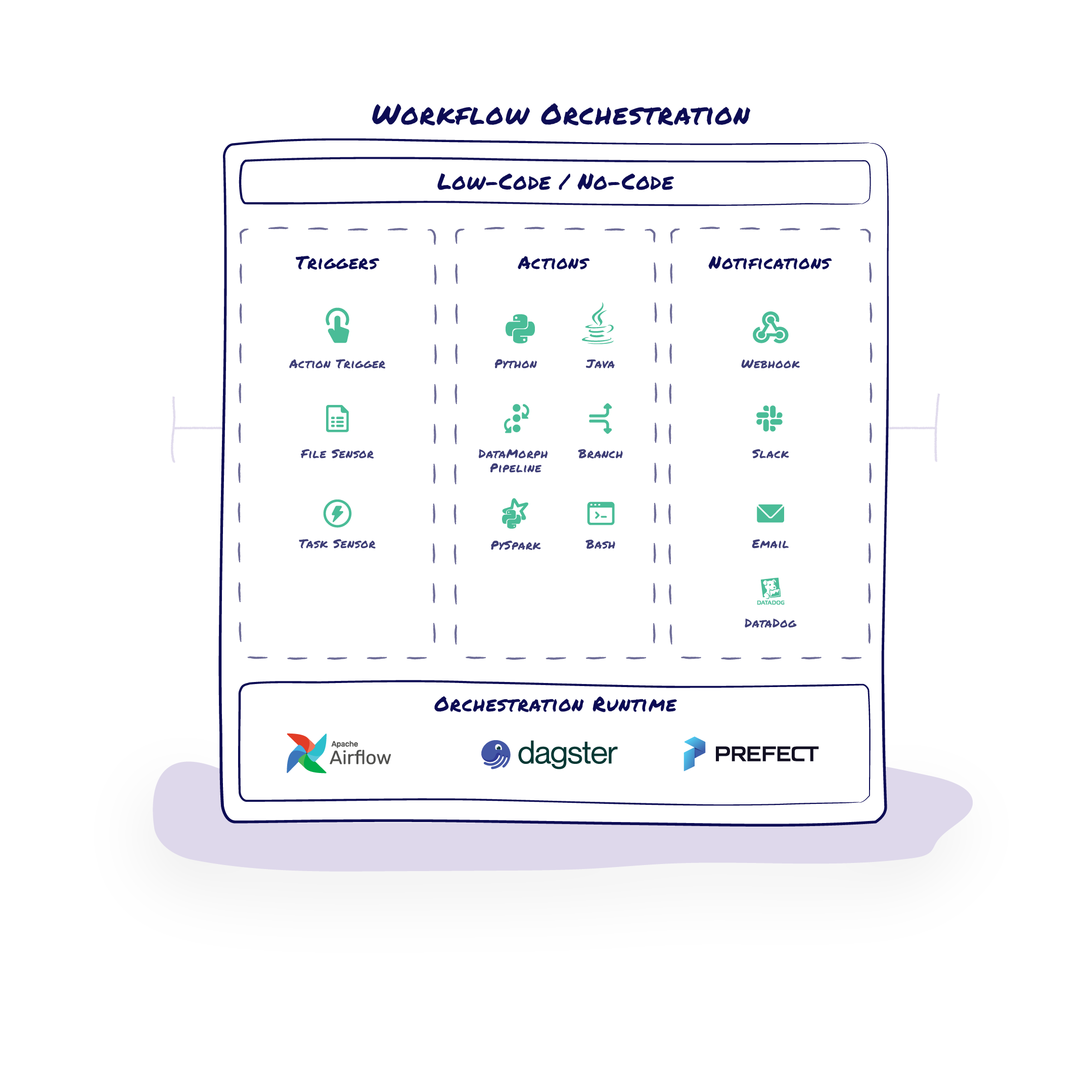
Workflows
Workflow orchestration is the process of managing and coordinating the execution of data pipelines which involves scheduling and automating the various tasks and processes involved in data pipelines, as well as error handling, alerting, and monitoring.
- Canvas with drag-and-drop interface for defining triggers, actions, and notifications
- Support for conditional execution of tasks and processes
- Scheduling and automation features
- Monitoring, alerting, and error handling tools
- Support for Airflow, Dagster, and Prefect Orchestration runtimes
Request a Demo

